
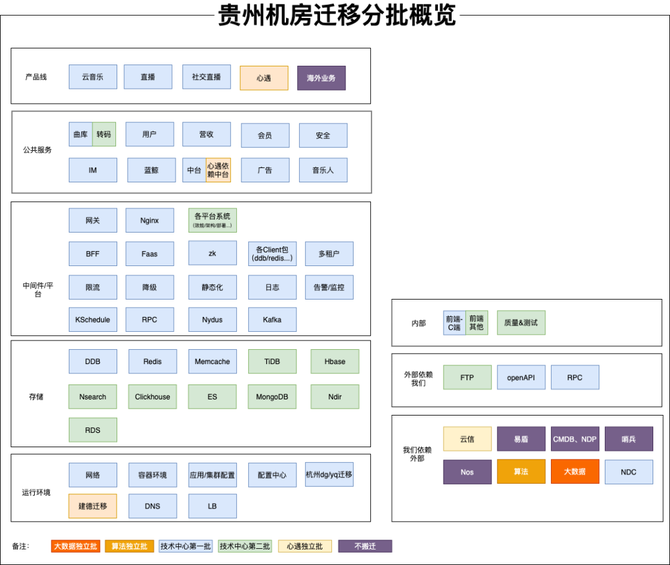
2023年确定要将云音乐整体服务搬迁至贵州机房,项目需要在各种限制条件下,保障2000+应用、100w+QPS的服务稳定迁移,是云音乐历史上顶级规模、人员最多、难度最高的技术项目。在此过程中,解决了大量历史技术债务,同时化解了大量新增系统性风险。以下为总体方案回顾。
此次需要云音乐以及旗下独立App的服务均整体迁移至贵州。涉及2000+应用、100w+QPS的稳定迁移,同时涉及中间件、存储、机房、三方依赖服务等整体的搬迁,搬迁规模大。
场景复杂。迁移规模大,带来更广的业务场景覆盖。而不同的场景对数据一致性要求不同、延迟敏感度不同。迁移方案需要仔细考虑各种场景带来的问题,并提供标准化的解决方案。
服务间依赖复杂。此次带来约2000+应用的搬迁,各服务间的调用和依赖情况复杂,在分批迁移方案中需要协调,以及解决迁移期间跨机房30msRT上升带来的问题。
在基础技术建设上,也有一些不足的情况,影响整体搬迁执行效率、迁移准确性。
云音乐有着大量的用户基数,此次搬迁要求:不停机迁移、不产生P2及以上事故。除此之外还有机器、网络带宽、网络稳定性、网络RT、迁移方案等限制条件。
杭州与贵州的长传带宽控制在200Gbps以内,且存在闪断的可能性,各迁移方案要重点考虑闪断带来的影响。
贵州机房与杭州机房之间网络延迟约30ms,各方迁移方案需重点考虑机房延迟带来的影响。
大数据、算法、云音乐技术中心串行搬迁,能轻松实现机器资源池共享,降低机器采购成本。
云音乐经过微服务之后,目前存在千+服务,各服务间依赖复杂。在贵州机房与杭州机房之间网络延迟约30ms的背景下,每产生一次跨区域调用,则RT上升30ms。
关于此处,会有同学认为优先B端可能会更稳,但优先采用B端优先,会有如下问题:
B端服务与C端服务相差较大,即使B端服务先行搬迁无问题,也不足以证明C端服务就一定没问题。
迁移期间,需要在贵州准备与杭州同等规模的机器资源,因此批次不可能不受到资源的限制。其主要受限制资源为:
因此,按照以上原则进行分批后,若资源仍不足,再根据团队/领域拆分出第二批
利于预热。在服务启动后,缓存、连接池需要随请求逐步预热,若流量直接全部打过来,可能会将服务打垮。
尽管做了各种稳定性保障来避免回滚,但是如遇到极端情况,仍有整体回滚的可能性。因此搬迁方案一定可回滚。
在切流过程中,杭州和贵州之间会有大量的服务访问、数据传输,从而可能突破长传带宽200Gbps的限制。因此切流方案中必须减少不必要的跨区域流量。
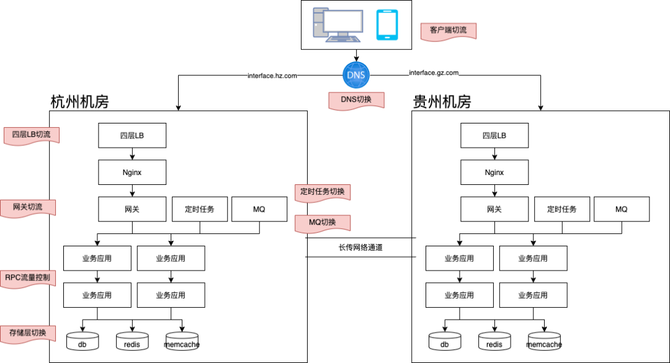
客户端切流。客户端通过动态切换域名配置,可实现流量的切换。切流算法可以与网关使用保持一致,我们在贵州迁移中就采用了此方案,从而大幅度降低贵州与杭州的长传带宽。
DNS切换。因DNS存在缓存过期,不适合作为流量控制的主要手段。在贵州迁移中,我们主要用其作为长尾流量的切换的手段。
四层LB切流、Nginx切流。主要由SA侧负责,因自动化和操作复杂度等因素,在贵州迁移中,四层LB切流只用于辅助切流手段,Nginx因过高的人工操作复杂度,不用于切流。
网关切流。网关作为服务端广泛接触的首要流量入口,其系统建设相对完善、自动化程度较高,因此作为主要切流手段。在此次迁移中,网关支持按用户ID、设备ID、IP进行按比例切流。
RPC流量控制。RPC流量路由策略与网关保持一致,依据切流比例,进行RPC流量调用。从而避免跨机房RT的不可控。
云音乐业务场景较多,不同场景下对数据一致性的要求也不一样,例如:营收下的订单类场景需要数据强一致性,而点赞需要数据最终一致性即可。
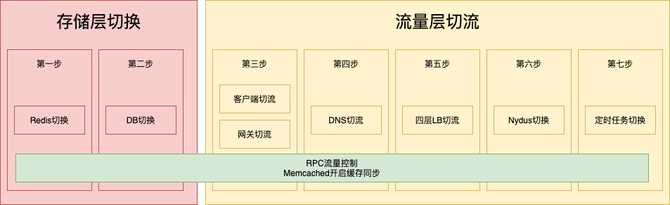
在涉及不同的存储时,也有着多种多样的迁移策略。对此,中间件以及各存储层支持了不同的迁移策略选择,各个业务基于不同的场景,选择正确的策略。迁移策略主要如下:

对以上切入点再次进行分类,可再次简化为流量层切流、存储层切换。在正式切流时,我们按照如下步骤进行切流。

全域的稳定性风险。我们在做一般的活动稳定性保障时,一般从活动的主链路出发,再梳理相关依赖,从而整理出稳定性保障&治理的重点。而这种方法确不适用于贵州机房迁移,从前面的分批概览图可得知:此次贵州机房迁移带来全域的稳定性风险。
因此整个项目组也在摸着石头过河,在此过程中,既有大的方案的设计,也有细枝末节的问题发现和推进处理。总结起来,我们总共从以下几个方面着手进行稳定性保障:
盘点梳理机器资源情况、网络带宽、迁移期间服务可用性要求等全局限制条件,从而确定分批方案、迁移思路。
主要盘点核数、内存。在此过程中,也推进了资源利用率优化、废弃服务下线等事宜。通过如下公式计算机器资源缺口:搬迁机器缺口 = 搬迁所需数量 -(可用数量+可优化数量)
需要控制云音乐的长传带宽总量 = 相对安全的带宽量相对安全的带宽量 = (长传带宽总量 / 2 x 0.8) - 已被占用带宽量
若业务允许全站停服迁移、或仅保障少量核心服务不挂,那么整体迁移方案会简单很多。因此业务对迁移期间的可用性要求,关乎着搬迁方案如何设计。最终讨论后确定,需要:迁移不产生P2及以上事故
因杭州和贵州机房同时部署,带来的服务节点数量、API数量、RPC数量翻倍风险
贵州公网质量如何?迁移至贵州之后是否会因公网质量上的问题,使用户体验差?由于云音乐用户基数大,且注重使用者真实的体验,这个是必须提前摸清的问题。若公网质量真的存在比较大问题,云音乐可能会停止贵州迁移项目。
云音乐C端服务当前的RT普遍在5~70ms之间,若增加30ms,有几率会使请求堆积、线程池打爆等风险。为避免此风险,我们从如下几个维度入手:
同一批次应用,基于用户ID、设备ID、IP进行Hash,实现同机房调用优先。
可能会出现单条中断的情况,在网络侧的表现为网络抖动。若单条线中断,那么出现故障的请求会重连至另一条线条线全部中断的情况。
各中间件、存储在切流期间,长传网络出现一些明显的异常问题时的表现、应对和兜底措施。例如ZK重连、重连失败后的重连风暴问题。
各服务在切流完成后,若仍经常使用长传网络,若长传网络出现一些明显的异常问题的表现、应对和兜底措施。
在贵州迁移项目中,我们对以上重点问题进行了梳理和解决,并制定了各种应急预案和极端情况下的回滚方案。
4)因杭州和贵州机房同时部署,带来的服务节点数量、API数量、RPC数量翻倍风险
因杭州和贵州机房同时部署,带来的服务节点数量、API数量、RPC数量翻倍风险
在服务节点数量、API数量、RPC数量翻倍后,主要对底层依赖带来连接、重连上的冲击,以及原有连接数上限的冲击。
在我们实际搬迁中,也因遗漏了这一点,导致线上ZK出现瓶颈,进而ZK挂掉的问题。其主要体现为在网关场景下存在数据推送瓶颈。最终通过网关侧的ZK拆分解决该问题。
除此之外,DB、Memcached、Redis、MQ等资源的连接数也可能会超过原先设定的上限,需要评估后进行调整。
批量调整配置中心值,因达到配置中心的性能瓶颈,导致配置变更时间过长,或服务挂掉。
批量的服务部署、重启,因达到K8S、构建机的性能瓶颈,导致部署、重启时间过长,或服务挂掉。
对迁移当晚核心路径上的服务进行集中访问、操作,因达到服务的性能瓶颈,导致访问超时、白屏、数据延迟、或服务挂掉的问题。
针对以上风险,我们重点对配置中心、K8S、贵州迁移管控平台等系统来进行了性能优化,以支撑整体迁移。
同城双活能力的缺失。为应对此风险,我们在逻辑上继续保留同城双活的能力,并暂时通过机房不同楼层的部署架构,来尽可能弥补同城双活能力的缺失。
机器上架、环境搭建、网络传输等需确保达到验收标准。为应对此风险,运维侧提供相关方案保障整体环境,并最终通过业务侧QA验收。
在贵州迁移前,已经有多次发生因配置变更错误带来的事故。而此项目带来从未有过的全域迁移,全域协作,大范围变更&发布,风险不可谓不高。在此过程中,通过了许多方式来保障事项的落地,其中比较关键的点,也是项目成功的关键点包括:
分工明确。在战略、战术、细节、事项推进等多个点均有有关人员把控,各司其职。
ZK的不稳定已导致云音乐最高出现P1级事故,在贵州迁移项目中,因网络环境、机房环境、迁移复杂度等因素,ZK服务挂掉的概率极大,因此必须不能对其强依赖。
最终中间件侧对其改造,支持ZK出现故障时,其注册信息降级到本地内存读取。并推进相关依赖方进行升级改造。
Nydus作为云音乐主力MQ产品,相较开源Kafka有更好的监控、运维等能力,Kafka在云音乐在线业务中已不再推荐使用。在贵州迁移中,MQ也有必要进行两地切换/切流。
在贵州迁移项目中,需要做大量的配置迁移、变更。其主要为:机房名、集群名、机器IP、机器Ingress域名的变化。而这些在配置中心、代码、自动化脚本、JVM参数中均有存在,此外,IP黑白名单还可能涉及到外部厂商的改造变更。
自动化扫描:通过代码扫描、配置中心扫描、JVM参数扫描、连接扫描等方式来进行问题发现。
人工梳理:外部厂商、不受Git管控的脚本、以及运维侧的配置(例如:存储层访问权限的黑白名单等)、以及自动化扫描可能的遗漏,由各研发、运维人员再次自行梳理。
核心应对杭州与贵州跨机房30ms RT和长传网络不稳定的风险。对循环调用、不合理依赖、强依赖进行改造。
因心遇强依赖云信,且云信IM为心遇核心业务功能,最终确定心遇为独立批次搬迁。因此心遇依赖的中台服务、存储、算法&大数据相关任务,均需拆分出来,不能与云音乐耦合,否则会产生跨机房调用,影响服务稳定性。
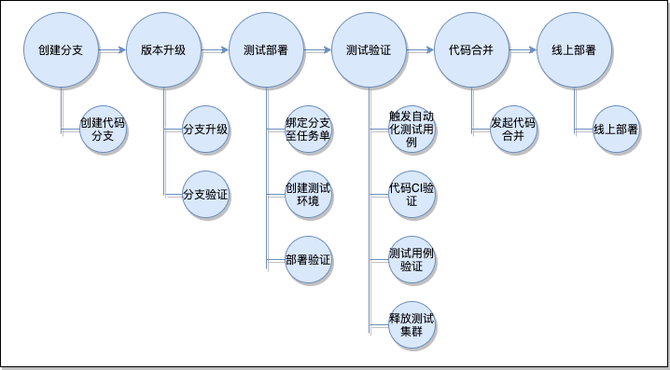
当前贵州迁移时整体会按照应用维度进行迁移、切流到贵州。因此对于中台租户型应用、多地域注册类型的应用需要拆分。
除了以上提到的历史技术债务处理和新增系统性风险,公共技术侧大都提供了标准化的接入、改造治理方式。例如:
贵州迁移中间件方案汇总。涵盖所有涉及中间件的迁移、切流、迁移策略、接入等指导方案。
贵州迁移升级指导。涵盖自动升级与手动升级、脚手架应用与非脚手架应用的升级方案。
贵州迁移线上部署指导。涵盖贵州线上部署前的各项必要准备事项,以及特殊应用的注意事项。
中台、多地域注册拆分指导。涵盖中台租户、多地域注册类型应用的拆分指导方案,及整体的拆分流程、验证要点等。
ddb、redis、memcached、KSchedule等非标治理。涵盖各中间件、存储的非标风险列表、解决的方法等。
杭州集群下线指导。涵盖杭州集群如何观察、缩容、下线、机器回收的指导方案。
贵州迁移整体大盘监控。提供了迁移相关全局比例,异常流量,异常比例,能够区分是迁移导致的还是本身杭州服务就有问题导致。同时集成资源层相关指标,判断是单个资源有问题还是全部资源有问题。
贵州迁移应用监控。提供了单个应用的贵州迁移监控,应用贵州杭州流量比例,异常流量,异常比例,能够区分是贵州还是杭州的问题。同时有资源相关的指标。
杭州集群与贵州集群的哨兵监控对比分析。提供指定应用的杭州和贵州集群在CPU利用率、线程池满、异常比例、RT超时等维度的对比。
客户端截流。在开启后,客户端将访问本地或CDN缓存,不再向服务端发送请求。
全站服务QPS限流至安全阈值。在开启后,全站的后端服务将限流调整至较低的安全阈值上,在极端情况下,避免因跨机房RT、跨机房传输、跨机房访问等因素的性能瓶颈引起服务端雪崩。
长传带宽监控&限流。在开启后,部分离线数据传输任务将会被限流。保障在线业务的带宽在安全水位下。
外网逃生通道。当出现长传网络完全中断,需要回滚至杭州。通过外网逃生通道实现配置、核心数据的回滚。
业务领域内的应急预案。各业务领域内,需要仔细考虑切流前的主动降级预案、切流中的应急预案。
批量重启。当出现局部服务一定要通过重启才能解决的问题时,将会启用批量重启脚本实现快速重启。当出现全局服务一定要通过重启才能处理问题时,需要当场评估问题从而选择全量重启或全量回滚至杭州。
应用搬迁范围、搬迁批次梳理明确。当上下游依赖的应用处于不同批次时,需要跨团队沟通协调。
切流SOP。包括切流前(前2天、前1天、前5分钟)、切流中、切流后各阶段的执行事项。
在服务迁移至贵州后,若杭州仍有流量调用,需排查流量来源,并推进流量下线或转移至贵州。先缩容观察,无正常流量、CDN回源等之后,再做集群下线。
此次贵州迁移,在各应用标准化治理之后,通过系统批量工具完成贵州各项环境的搭建、测试环境的批量部署。
贵州测试环境批量创建。通过迁移工具,实现贵州测试集群的批量创建、配置批量迁移等。
应用自动化升级。通过自动升级平台,实现大规模应用的批量升级,支持了各组件、各应用的多次快速验证、快速升级。
测试环境自动化部署。通过自动化部署脚本,为支持测试环境能够多次、高效演练。
SOP梳理&平台建设。通过SOP平台,将SOP文档沉淀为系统能力,实现各SOP能力的系统化。
迁移监控大盘建设。通过细化梳理监控指标,构建监控大盘,掌握各应用、各组件在切流期间的表现。
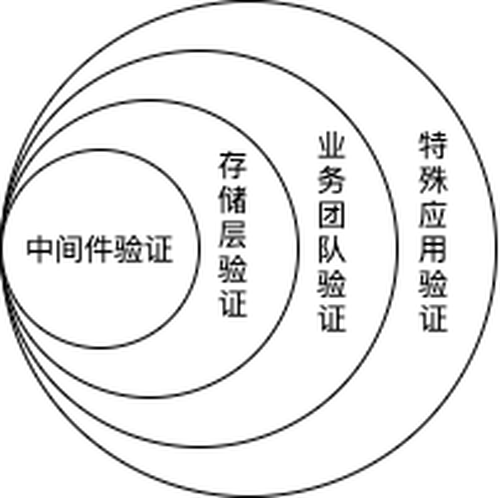
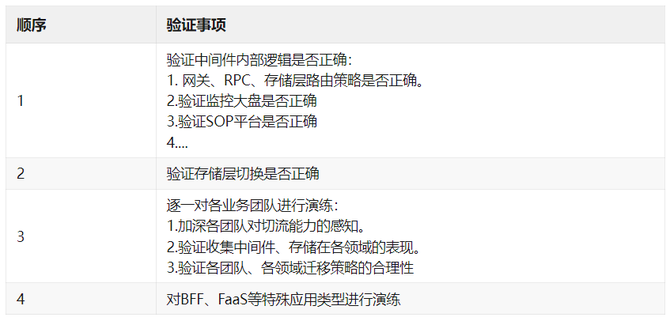
在云音乐主站正式切流前,先对云音乐旗下独立App进行了线上搬迁验证,保障云音乐迁移时的稳定性。

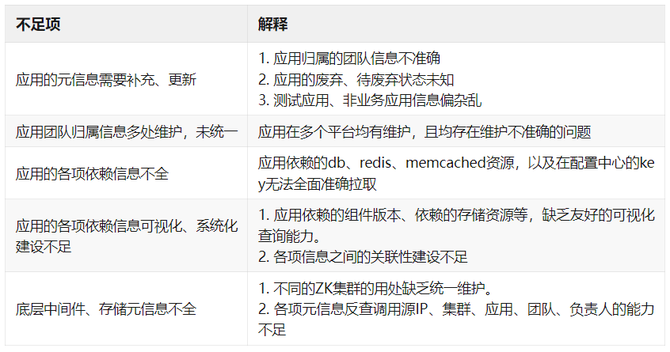
在贵州迁移过程中,做了历史技术债务处理、标准化接入方式,后续可针对各项元信息的创建、更新、销毁进行标准化、系统化建设。例如:
借助组件升级平台,实现组件发布、升级的标准化、系统化。DB、Redis、Memcached、ZK的申请、使用、接入等标准化、防劣化。
目前应用可做配置的入口有:配置中心、properties文件、props文件、JVM参数、硬编码。不同的中间件提供出的配置方式也各有不同,所以各应用的配置比较五花八门。因此可做如下改进:
明确各种配置入口的使用标准。比如:何时建议用配置中心?何时建议用JVM参数?